Core concepts
Jobs
Jobs are used to execute extended distributed workflows. They are similar to functions in that they are executed on dynamically provisioned hardware, and can run in parallel.
However, jobs provide some additional functionality.
Jobs provide support for progress monitoring and cancellation while the execution is in flight.
Job statuses and job results can be queried at any time, from anywhere in the codebase.
Jobs can hold locks, preventing certain kinds of race conditions.
import multinode as mn
@mn.job()
def process_data(input_data):
output_data = perform_extended_computation(input_data)
yield output_data
Yield, not return - exposing intermediate results
Why does a job yield rather than return? If the job takes several minutes to run, you may want to expose intermediate results before the job is finished.
For example, to produce a progress bar, your job can yield a progress percentage, which is a value between 0% and 100% that is increased upon reaching certain milestones. This mechanism would be impossible to implement with a simple return statement.
The example at the end of this section demonstrates this idea.
Methods on the job object
.start
This creates a new job, and returns an auto-generated UUID for this job.
job_id = process_data.start(input_data)
.get
This returns a JobInfo object (or raises a JobDoesNotExist error if there exists no job with the ID provided).
job_info = process_data.get(job_id)
The JobInfo object has three important fields:
.status- an enum, whose possible values are"PENDING","RUNNING","SUCCEEDED","FAILED","CANCELLING","CANCELLED"..result- the value most recently yielded by the job..error- an error message if.statusis"FAILED", orNone, otherwise.
.cancel
This cancels a job (or raises a JobDoesNotExist error if there exists no job with the ID provided).
process_data.cancel(job_id)
.remove
This removes data about a job from the system. If the job is still "RUNNING" or "PENDING", it will be cancelled first.
process_data.remove(job_id)
There is no expiry time for job data. The data is persisted until .remove is called.
.list_ids
This lists the IDs of existing jobs in the system.
ids_of_existing_jobs = process_data.list_ids()
Implementing an API for managing job lifecycles
Let's expose our job to our users as an API. The API will be implemented as a service, which calls the various methods on the job object from within.
import multinode as mn
from fastapi import FastAPI
app = FastAPI()
@mn.job()
def process_data(input_data):
output_data = perform_extended_computation(input_data)
yield output_data
@app.post("/jobs")
def start_job(input_data):
job_id = process_data.start(input_data)
return job_id
@app.get("/jobs/{job_id}")
def get_job_info(job_id):
return process_data.get(job_id).result
@app.put("/jobs/{job_id}/cancel")
def cancel_job(job_id):
process_data.cancel(job_id)
@mn.service(port=80)
def main():
app.run()
Gracefully handling cancellations
Sometimes, we may want to perform some cleanup when a job is cancelled. When the cancellation request is propagated to the job runtime, a JobCancelled error is raised. We can handle this error just like any another error using try-except-finally blocks.
import multinode as mn
from multinode.errors import JobCancelled
@mn.job()
def process_data(input_data):
try:
output_data = perform_extended_computation(input_data)
yield output_data
except JobCancelled:
# e.g. log the cancellation event
finally:
# Clean up
Any cleanup action should finish within 5 minutes of the JobCancelled error, after which the job will be forcibly killed.
Locking: handling race conditions
Sometimes, we need to ensure that certain jobs do not run in parallel with one another, as this would lead to race conditions.
Suppose we have a job that performs maintenance on database tables. It is essential that we never have two concurrent job executions modifying the same table, since that may leave the table in an inconsistent state.
This issue can be resolved by locking on the table ID.
@app.post("/jobs")
def start_job(job_definition):
try:
process_data.start(
input_data,
lock=job_definition.table_id
)
except LockAlreadyInUse:
# Exception raised if another job is locking on the same table_id
return Response(
status_code=400,
content="Conflict with another job"
)
Distributing a job workload using functions
Jobs can be optimised by parallelising the workload over multiple workers. This can be achieved by invoking functions from within the job.
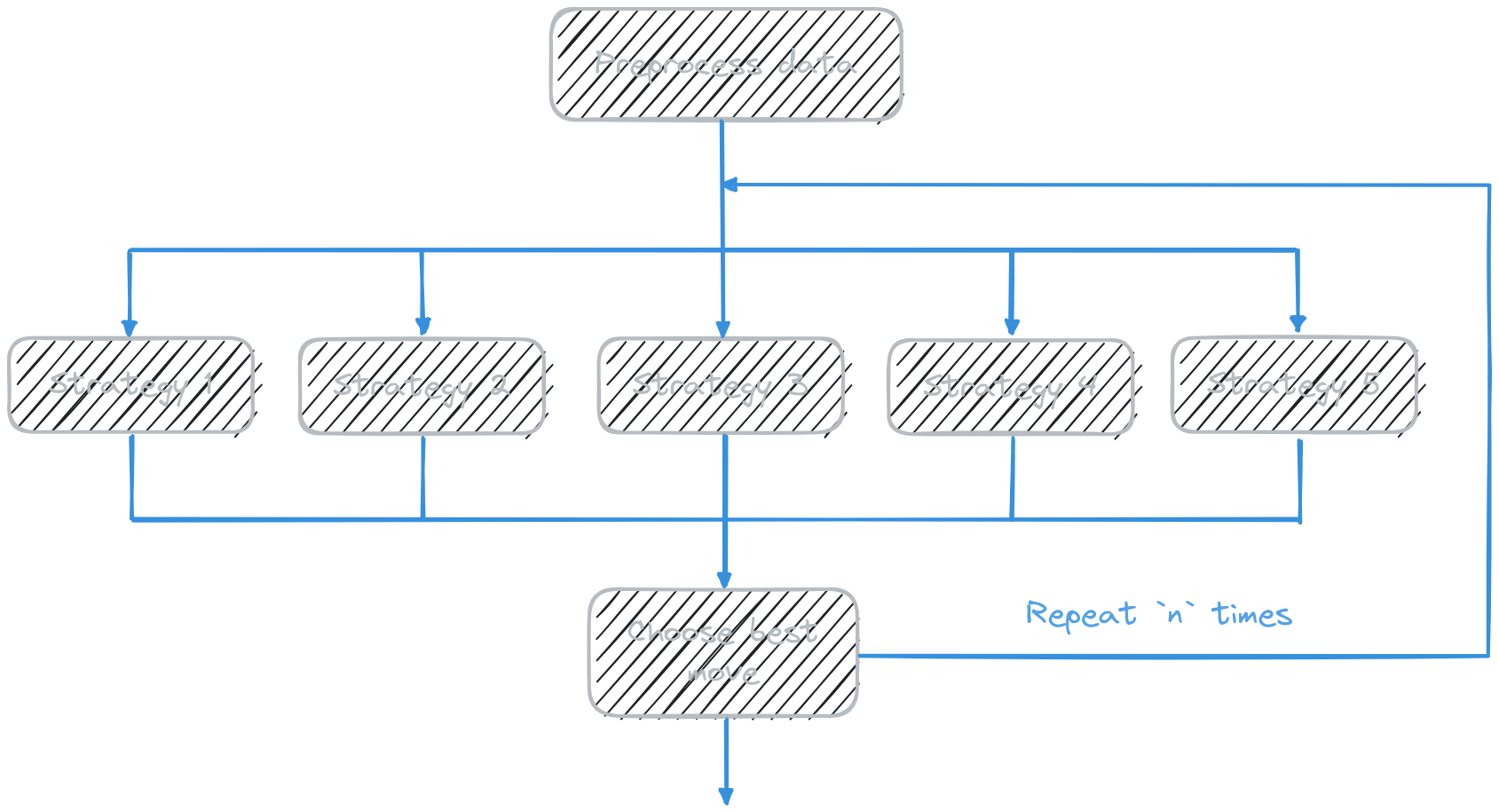
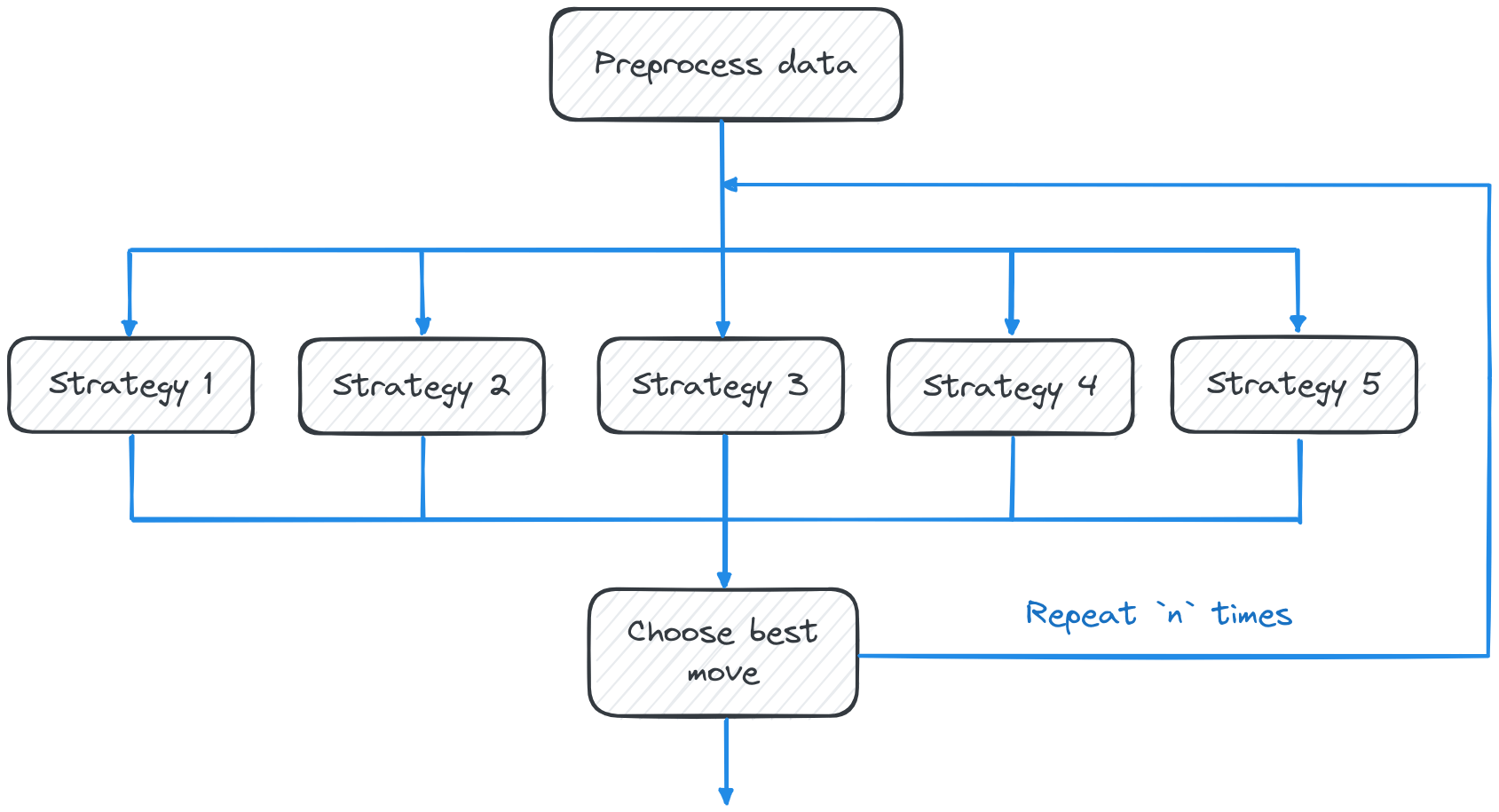
Suppose we are building an app that calculates the best next n moves in a chess game.
We calculate one move at the time, based on previous moves that have already been calculated. At each step, five competing strategies are used to suggest candidate moves. Then, out of the five candidates, the one with the highest evaluation is selected.
The workflow is as follows:
- Data preprocessing. This requires a medium amount of compute and a medium amount of memory. It cannot be parallelised.
- Candidate generation. The five strategies can run in parallel with one another. Each requires heavy compute, but only a modest amount of memory.
- Ranking based on evaluations. There is no need to parallelise this because this is quick to begin with.
Steps 2 and 3 are repeated n times.
This calculation is extremely easy to implement in multinode!
STRATEGIES = [
SimpleStrategy(),
GreedyStrategy(),
CarlsenStrategy(),
MittensStrategy(),
KasparovStrategy(),
]
@mn.job(cpu=0.1, memory="1GiB")
def calculate_next_n_moves(board_data, n):
preprocessed_board_data = preprocess_data(board_data)
chosen_moves = []
for i in range(n):
arguments = [
(preprocessed_board_data, chosen_moves, s)
for s in STRATEGIES
]
candidates_for_next_move = suggest_candidate_move.map(arguments)
best_next_move = choose_best_move(candidates_for_next_move)
chosen_moves.append(best_next_move)
yield chosen_moves
@mn.function(cpu=4, memory="32GiB")
def preprocess_data(board_data):
# Do some preprocessing
return preprocessed_board_data
@mn.function(cpu=16, memory="4GiB")
def suggest_candidate_move(preprocessed_board_data, previous_moves, strategy):
# Do some heavy computations depending on the strategy
return suggested_move
# NB not a @mn.function(), since this is inexpensive
def choose_best_move(candidate_moves):
return max(moves, key=lambda m: m.evaluation)
# Now you can wrap this job as an API
Incidentally, this example clearly demonstrates the benefits of using yield rather than return. If we call .get(job_id) while the job is in progress, the .result field will contain the moves that have been generated so far. And of course, if we cancel the job midway, we retain access to the moves that have already been generated.